What is Feature Engineering?
- Ishan Deshpande

- May 20
- 4 min read

Imagine trying to build a house using broken bricks, missing measurements, and poor-quality materials.
Even with the best architect and workers, the final structure may still be weak.
Machine Learning works in a very similar way.
No matter how powerful your ML algorithm is, if the data is messy, incomplete, or poorly prepared, the model will struggle to learn properly.
This process of preparing and improving data before training a model is called Feature Engineering
And in real-world ML projects, this step is often more important than the algorithm itself.
What is a Feature?
A feature is simply an input variable or column used by the ML model to make predictions.
Example
Suppose we want to predict house prices.
Area | Bedrooms | Location | Price |
1200 sq ft | 2 | Pune | ₹50L |
Here:
Area
Bedrooms
Location
are features.
And:
Price
is the target/output.
So, What is Feature Engineering?
Real-world data is rarely clean and perfect.
Sometimes:
Values are missing
Text cannot be understood by machines
Numbers are on completely different scales
Some columns are useless
Feature Engineering is the process of converting this messy raw data into meaningful and machine-friendly data.
Let’s discuss some import steps which are part of Feature Engineering
1. Handling Missing Values
Let’s say you collected customer data for an ML model.
Name | Age | Salary |
Rahul | 25 | ₹50K |
Priya | NULL | ₹70K |
Now imagine asking the ML model “Learn patterns from this.”
The model immediately gets confused because one value is missing.
Most ML algorithms do not understand blank values the way humans do.
How do we fix it?
Option 1 — Remove the missing rows
Works well if only a few records are incomplete. For example, only 2 out of 10,000 rows are missing.
Option 2 — Fill the missing values
If significant values are missing, removing rows could destroy useful information.
Instead, we can replace them using:
Average (Mean)
Median
Most common value (Mode)
But when do we use each one?
Mean (Average) → Used when data is fairly balanced without extreme outliers.
Example: Average exam marks.
Median → Preferred when data contains very high or very low values because it is less affected by outliers.
Example: Salary data where a few people earn extremely high salaries.
Mode → Used mostly for categorical/text data where we replace missing values with the most frequent category.
Example: Replacing missing “City” values with the most commonly occurring city.
2. Encoding
Humans easily understand this:
City |
Pune |
Mumbai |
Delhi |
But for ML models, text is meaningless. Machines only understand numbers.
So we convert categories into numerical form. This process is called Encoding
Simple Encoding Example
Label Encoding
Pune = 1 Mumbai = 2 Delhi = 3
One-Hot Encoding
City | Pune | Mumbai | Delhi |
Pune | 1 | 0 | 0 |
Mumbai | 0 | 1 | 0 |
Delhi | 0 | 0 | 1 |
But here’s the interesting part...
If we use:
Pune = 1 Mumbai = 2 Delhi = 3
Some ML models may incorrectly assume: Delhi > Mumbai > Pune
even though cities have no ranking.
That’s why One-Hot Encoding is often preferred.
When encoding becomes tricky
Imagine encoding 2500 cities, suddenly your dataset becomes huge.
This is where smarter encoding techniques are used.

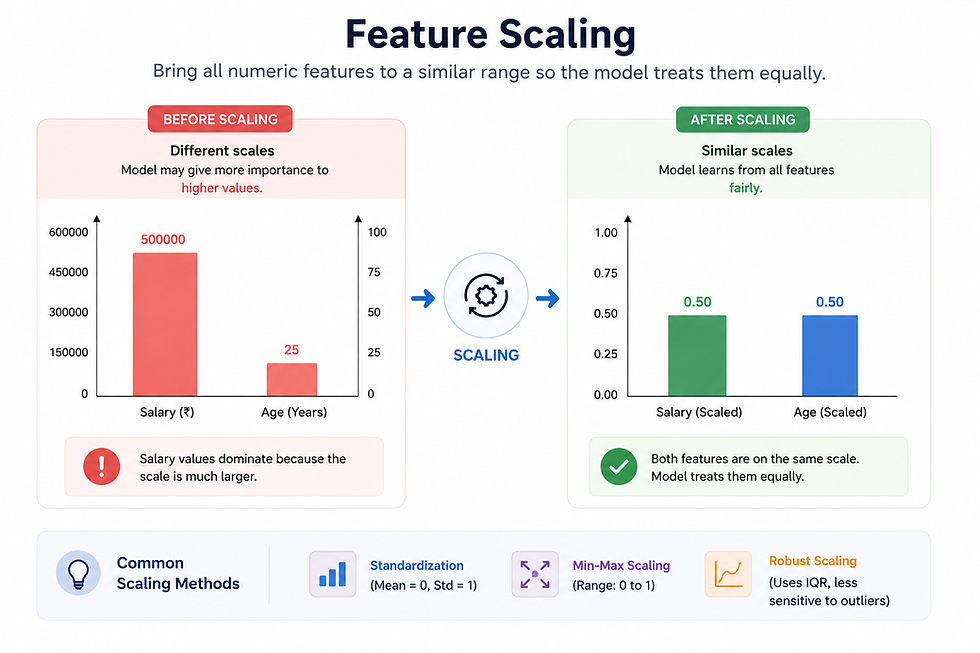
3. Feature Scaling
Imagine a race between:
A person carrying 5kg
A person carrying 500kg
Not exactly fair, right? Something similar happens in ML.
Consider this dataset:
Age | Salary |
25 | 500000 |
Salary values are much larger than Age values.
Some algorithms may give Salary more importance simply because the numbers are bigger.
Not because it’s actually more important.
Feature Scaling brings values into a similar range so models can learn more fairly.
Important thing beginners should know
Not every algorithm needs scaling.
Tree-based algorithms like:
Decision Trees
Random Forest
XGBoost
usually work perfectly fine without it.
But algorithms like:
KNN
SVM
Neural Networks
often improve significantly after scaling.
4. Feature Creation
Sometimes raw data hides useful insights. A smart ML engineer creates new features from existing ones, which help ML algorithm to learn better.

Why this matters
Many times better features improve accuracy more than changing algorithms.
5. Log Transformation
Real-world data is often unbalanced.
For example:
Most salaries may be between ₹20K–₹80K
But a few people may earn ₹50 Lakhs+
These very large values can dominate the learning process.
Log Transformation reduces the impact of extremely large values by compressing the gap between small and large numbers.

6. Feature Selection
Not every column helps the model. Some features add noise, Increase confusion & Reduce performance
Example
For predicting house prices:
Useful:
Area
Location
Number of bedrooms
Probably useless:
Owner’s age
Removing irrelevant features helps models focus on what truly matters.
Final Thoughts
Feature Engineering is where Machine Learning truly begins.
Before a model can learn patterns:
Data needs to be cleaned
Organized
Balanced
Simplified
Transformed into something meaningful
And this is exactly what Feature Engineering does. The better the features, the smarter the model becomes.
In the upcoming blogs, we’ll go through few more important concepts and then jump right into the Algorithms.
Until next time — stay curious, keep learning!


